Why AI Quality Degrades on Large Tasks — And How Multi-Agent Architecture Solves It
AI models lose accuracy on long, complex tasks due to context window limits and attention degradation. Learn why this happens and how multi-agent architecture fixes it.
You ask ChatGPT to analyze 50 companies. The first ten get detailed, thoughtful breakdowns. By number twenty-five, the descriptions are noticeably shorter. By number forty, it's making things up.
You're not imagining it. This is a real, measurable problem. And every major AI model does it.
A 2026 study from Mount Sinai Hospital put hard numbers on the issue: a single AI agent's accuracy dropped from 73.1% to 16.6% when workload scaled from 5 to 80 simultaneous tasks. Not a small decline. A collapse.
This article explains why AI quality breaks down on large tasks, what causes it at a technical level, and what architecture actually solves it.
The Problem Everyone Experiences But Nobody Explains
If you've used ChatGPT, Claude, Gemini, or any large language model for complex work, you've seen this pattern:
You give it a list of items to process. The first few items get excellent output. Midway through, quality quietly drops. By the end, the AI is cutting corners — shorter responses, missing details, or outright fabrication.
This happens with every major model, regardless of what the marketing says. Independent research from Chroma tested 18 frontier models in 2025 and confirmed that every single one degraded as input length grew. No exceptions.
The problem gets worse as tasks get more complex. Asking an AI to analyze one company is fine. Asking it to analyze fifty in a single session pushes it past its reliable operating range.
This matters because the tasks where AI could save the most time — large batch processing, comprehensive research, multi-step analysis — are exactly the tasks where this degradation hits hardest.
Why It Happens: Context Windows and Attention
To understand the problem, you need to understand two concepts: context windows and attention.
What Is a Context Window?
A context window is the total amount of text an AI model can "see" at one time. Think of it as the model's working memory. Everything you've said, everything it's said back, every document it's read, and every instruction it's following — all of it has to fit inside this window.
In 2026, context windows have gotten large. Some models advertise 200,000 tokens. A few claim 1 million. Meta's Llama 4 Scout technically supports 10 million tokens — enough for roughly 15,000 pages of text.
These numbers sound impressive. But advertised capacity and actual usable capacity are very different things.
The Gap Between Claimed and Effective
Research consistently shows that models perform reliably at only 60-70% of their advertised context window. A model claiming 200,000 tokens starts degrading around 130,000. A model with a 1-million-token window? It struggles past 600,000-700,000 tokens.
One researcher put it bluntly: the advertised window is a ceiling, not a performance guarantee.
This gap exists because of how attention works.
How Attention Breaks Down
Large language models use a mechanism called "attention" to decide which parts of their input are most relevant to the current output. When the context is short, the model can attend to everything effectively. As the context grows, the model has to distribute its attention across more and more information.
Think of it like a person reading a 10-page report versus a 500-page report. With 10 pages, you remember the key points from each section. With 500 pages, you forget details from early chapters by the time you reach the end. You pay more attention to what you've read recently and less to what came first.
AI models do the same thing. Research has identified a specific pattern called "lost in the middle" — models tend to pay the most attention to information at the beginning and end of their context, while information in the middle gets compressed or ignored.
This is why company number 1 and company number 50 in your analysis might get reasonable treatment, but companies 20 through 35 get progressively worse coverage. They're stuck in the middle of the model's attention window.
Why Hallucination Increases With Length
As the context fills up and attention degrades, something worse than shortcuts happens: the model starts fabricating information.
This is called hallucination. It occurs when the model generates text that sounds confident and plausible but is factually wrong. Hallucination rates increase with context length because the model has less reliable information to draw on and more pressure to produce output.
If you ask an AI to analyze 50 companies and it hasn't retained accurate information about companies 30 through 45, it faces a choice: admit it doesn't know, or generate something that sounds right. Models are trained to generate fluent, helpful text — which means they lean toward producing plausible-sounding information even when they don't have the data to back it up.
Context Rot: The Technical Name for the Problem
Researchers have given this phenomenon a name: context rot.
Context rot refers to the progressive degradation of an AI model's performance as its context window fills up. It's not a sudden cliff — it's a gradual decline. Each additional piece of information slightly reduces the model's ability to use all the information it already has.
The effect is well-documented. Chroma's 2025 research tested 18 frontier models and found that none of them use their context uniformly. Performance grows increasingly unreliable as input length grows, with models paying disproportionate attention to recent information and losing track of earlier content.
Context rot affects different types of tasks differently. Simple retrieval tasks — "find this specific fact in this document" — hold up reasonably well. Synthesis tasks — "analyze all of these data points and draw conclusions" — degrade much faster because they require the model to hold many pieces of information in mind simultaneously.
The Cost Problem
Context rot isn't just a quality problem. It's an economic problem.
Processing longer contexts costs more money. Token pricing is directly tied to context length. If you're sending 100,000 tokens of context to a model, you're paying for all 100,000 — even if the model is only effectively using 60,000 of them.
Worse, models burn more computational resources as context grows. Processing time increases. Latency spikes. In the Mount Sinai study, the single-agent system used 65 times more computing resources than the multi-agent system to achieve dramatically worse results.
So you're paying more money for worse output. That's the worst of both worlds.
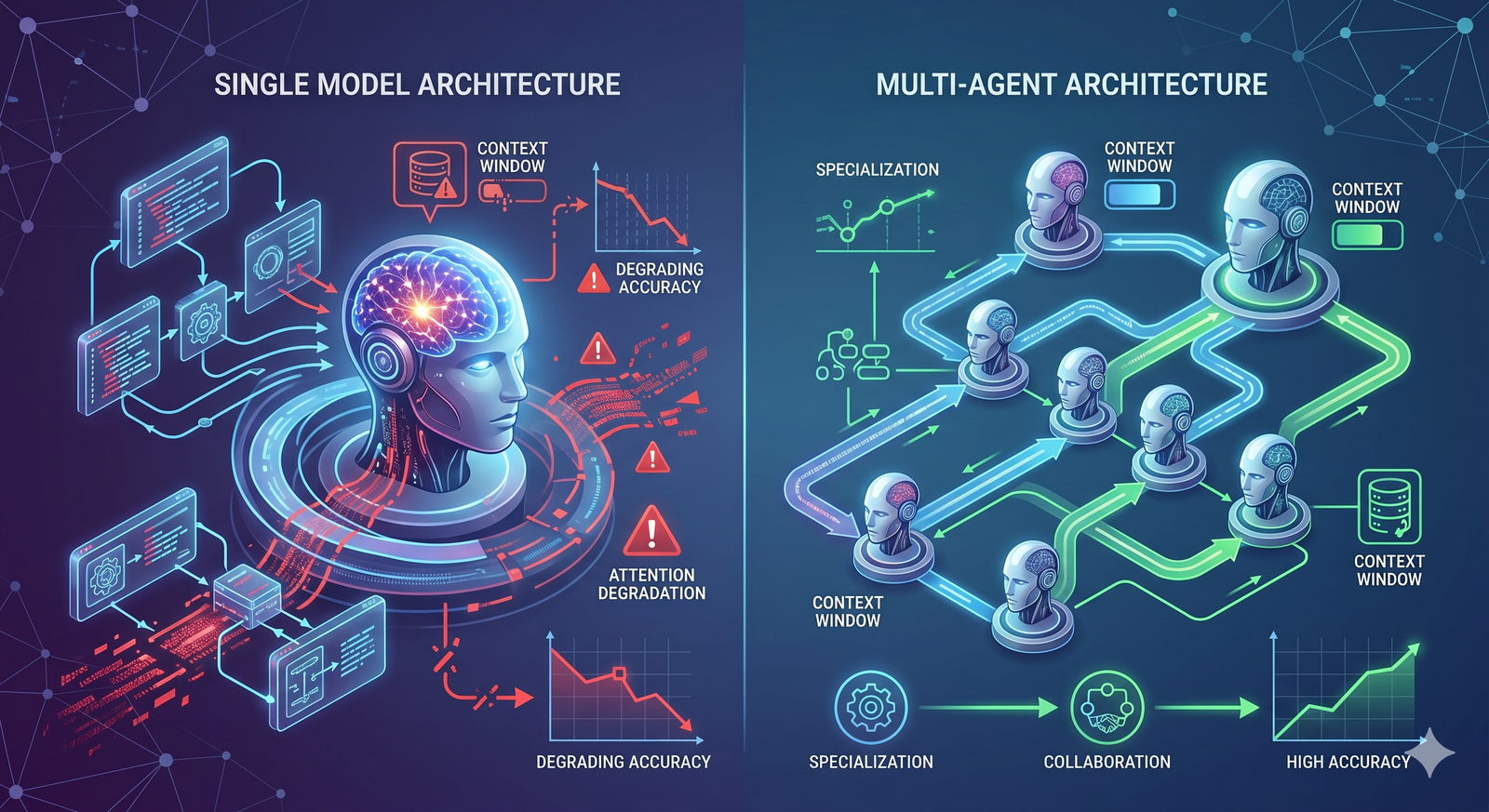
How Multi-Agent Architecture Solves This
The solution to context rot isn't bigger context windows. Research shows that bigger windows just push the degradation point further out — they don't eliminate it. The real solution is to avoid overloading a single context window in the first place.
That's what multi-agent architecture does.
The Core Idea
Instead of one agent processing everything in one giant context window, the work gets split across multiple agents, each with its own fresh, independent context window.
If you need to analyze 50 companies, you don't ask one model to do all 50 sequentially. You deploy 50 agents, each analyzing one company. Every agent gets a clean context window dedicated entirely to its one task. Agent number 50 has the same fresh attention and focus as agent number 1.
A coordinator agent manages the workflow — dividing the work, distributing it, collecting results, and assembling the final output.
Why It Works
The key insight is simple: each agent operates within the reliable range of its context window.
Instead of one agent using 100% of a 200,000-token window (and degrading past 130,000), each sub-agent uses maybe 10,000-20,000 tokens — well within the range where models are accurate and reliable.
Anthropic confirmed this when they built their multi-agent research system. Their analysis found that token usage explains 80% of the performance variance in their evaluations. Multi-agent systems work better because they can apply more total reasoning capacity to a problem while keeping each individual agent's context clean and focused.
Their multi-agent system outperformed a single-agent approach by 90.2% on research tasks. The gains were especially large for tasks that required exploring many independent directions at once — exactly the type of broad, parallel work where context rot hits hardest.
The Data Is Clear
The Mount Sinai study provides the most controlled comparison. Under identical conditions with identical models:
At 5 tasks: single-agent accuracy was 73.1%, multi-agent was 90.6%. Modest difference.
At 80 tasks: single-agent accuracy was 16.6%, multi-agent was 65.3%. Massive difference.
The multi-agent system didn't just maintain quality — it did so while using 65 times fewer computing resources. Distributing work across specialized agents with clean contexts is both more accurate and more efficient than overloading a single agent.
When to Use Multi-Agent Architecture
Multi-agent architecture isn't necessary for every task. Here's a practical decision framework.
Use a single agent when: the task is simple, the input is short, and everything fits comfortably within one context window. A single question, a short document summary, a quick calculation — these don't need multi-agent orchestration.
Use multi-agent architecture when: the task involves processing multiple items (more than 10-15), requires combining multiple types of analysis, or involves inputs that approach 50% of the model's context window. If you notice quality dropping as the task gets bigger, that's the signal.
The practical threshold: if a single agent completes the task and the quality of the last item is as good as the first item, you're fine with one agent. The moment quality starts dropping off toward the end, multi-agent architecture will improve your results.
What This Means for How You Use AI
The most important takeaway is this: the limitation isn't the model. It's how you use it.
The same model that produces garbage at 80 sequential tasks can produce excellent results when those tasks are distributed across a multi-agent system. The intelligence of the model didn't change. The architecture around it did.
This has practical implications for anyone using AI for real work:
Don't blame the model for bad output on large tasks. The model isn't broken. You're asking it to work outside its reliable operating range. The solution is architectural, not a better prompt.
Break large tasks into smaller, independent pieces. Even without a formal multi-agent platform, you can get better results by processing items in small batches rather than one massive prompt.
Evaluate AI tools on large tasks, not small ones. Any AI looks good on a 5-item test. The real test is what happens at 50 or 100 items. That's where architecture separates the platforms that scale from the ones that don't.
The context window problem is real, but it's solvable. The models themselves are remarkably capable. The question is whether the systems built around them are designed to keep them within their reliable range — or whether they're set up to fail by overloading a single agent until quality collapses.