How AI Model Routing Works: Why One Model Isn't Enough Anymore
Different AI models excel at different tasks. Model routing automatically selects the best model for each job. Learn how it works, why it matters, and what it means for cost and quality.
Claude is better at writing. GPT is better at analysis. Gemini is stronger at multimodal tasks. DeepSeek is faster at code.
If you've used more than one AI model, you already know this intuitively. Different models have different strengths. No single model wins at everything.
But most people and most teams still use one model for all their work. One subscription. One interface. One model handling writing, research, coding, analysis, and everything else — even when it's not the best choice for half those tasks.
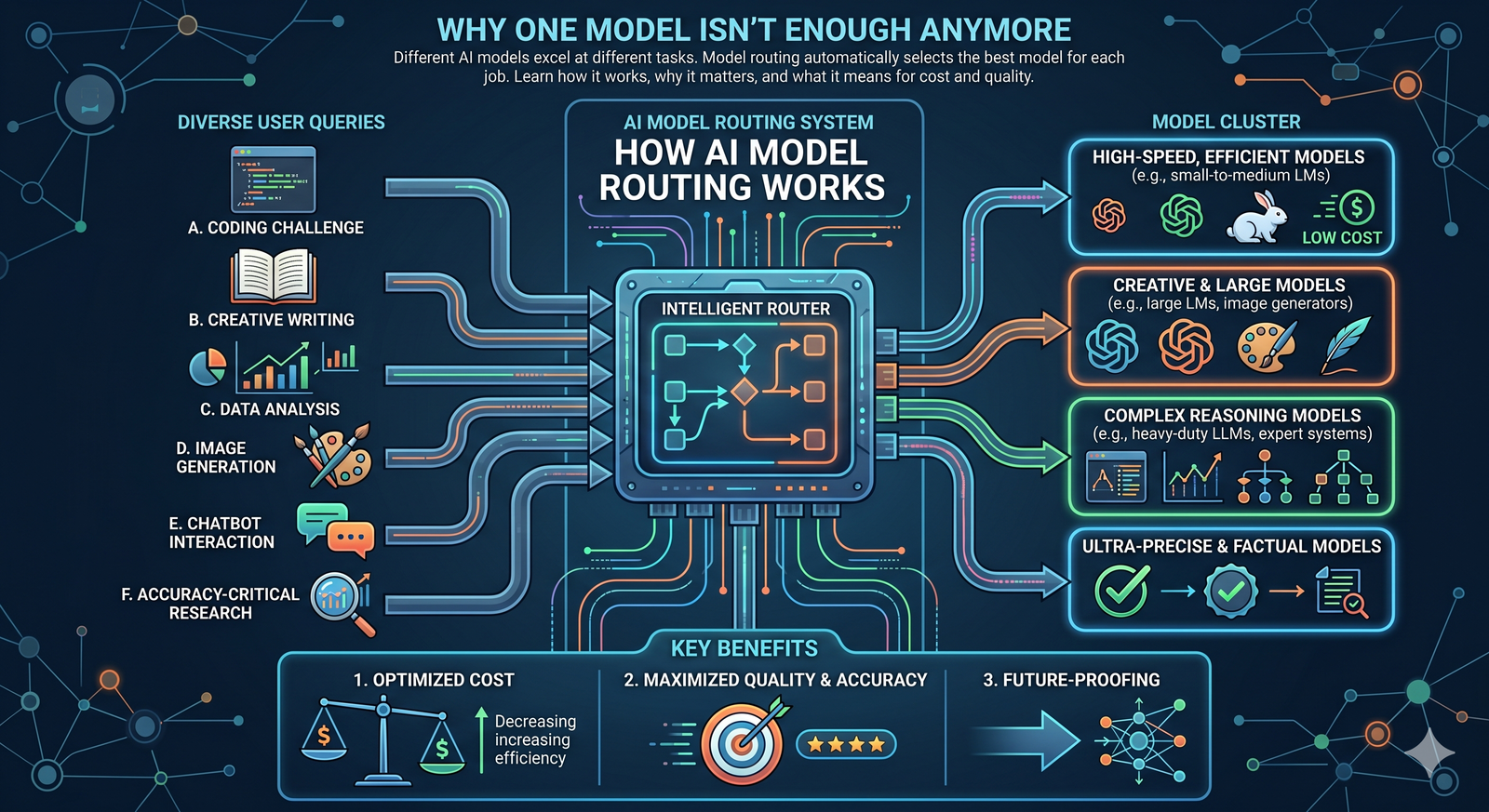
Model routing changes that. Instead of picking one model and hoping for the best, a routing layer automatically selects the best model for each task based on what the task actually requires.
This article explains how model routing works, why it's becoming standard in 2026, and what it means for cost, quality, and how teams use AI.
The Problem With Using One Model for Everything
The "pick one model" approach made sense when there were only a few options and the differences between them were small. That's no longer the case.
In 2026, there are hundreds of large language models available. They range from massive frontier models that cost several dollars per million tokens to lightweight models that cost pennies. They range from generalists that handle everything reasonably well to specialists fine-tuned for specific domains.
Benchmarking data consistently shows meaningful performance gaps between models on different task types.
Claude Opus 4.6, Anthropic's flagship, scores highest on coding tasks and long-form reasoning. Gemini 3.1 Pro from Google leads on reasoning benchmarks and multimodal understanding. GPT-5.4 from OpenAI remains the strongest general-purpose model with the broadest knowledge base. Smaller models like GPT-5 mini deliver surprisingly strong performance at a fraction of the cost for routine tasks.
The cost differences are just as significant. One benchmarking study found that Claude 4.5 Sonnet delivers a 70.6% benchmark score at $0.56 per task, while GPT-5 mini delivers 59.8% at just $0.04 per task. For a team processing thousands of tasks daily, that 14x cost difference isn't trivial.
Using one expensive model for everything means you're overpaying for simple tasks. Using one cheap model for everything means you're getting poor results on complex tasks. Neither approach is optimal.
What Is Model Routing?
Model routing is a system that sits between your application and multiple AI models. When a request comes in, the routing layer evaluates what the task requires and sends it to the model best suited to handle it.
Think of it like a hospital triage system. A patient comes in. The triage nurse doesn't send everyone to the same specialist. A broken arm goes to orthopedics. Chest pain goes to cardiology. A routine checkup goes to a general practitioner. The triage step matches the need to the right resource.
Model routing does the same thing with AI requests. A simple classification task goes to a fast, cheap model. A complex research question goes to a powerful reasoning model. A code generation request goes to a model optimized for programming.
The user doesn't need to know which model handles their request. They describe what they need, and the routing system handles the selection automatically.
How Routing Actually Works
There are three main approaches to model routing. Each makes different trade-offs between control, flexibility, and complexity.
Static Routing (Task-Based Rules)
The simplest approach. You define rules in advance: writing tasks go to Model A, coding tasks go to Model B, simple questions go to Model C. The routing is a lookup table — task type maps to model.
This is the most predictable and auditable approach. You always know which model handled which request and why. You can reproduce any result by sending the same task type to the same model.
The downside is rigidity. If a new model becomes available that's better at coding, you have to manually update the routing rules. And tasks don't always fit neatly into predefined categories.
Best for: teams with well-defined, recurring task types where consistency and auditability matter most.
Dynamic Routing (AI-Based Classification)
A more sophisticated approach. Instead of predefined rules, a lightweight classifier model evaluates each incoming request and decides which model should handle it based on the request's complexity, type, and requirements.
OpenRouter's Auto Router does this — it uses AI to analyze each prompt and route it to an appropriate model automatically. RouteLLM, an open-source router, classifies prompts as either complex or simple and routes them to either a strong or weak model based on a configurable threshold.
Dynamic routing adapts automatically to new types of requests without manual rule updates. But it adds a classification step before every request (typically 50-200 milliseconds of extra latency) and introduces a stochastic element — the same request might route to different models on different occasions.
Best for: teams handling diverse, unpredictable task types where manual rule maintenance would be impractical.
Hybrid Routing
Combines both approaches. A planning agent breaks complex requests into subtasks. Each subtask gets routed to the appropriate model based on what it requires — some subtasks use rules-based routing, others use dynamic classification.
This is the approach most advanced multi-agent systems use. The orchestrator agent plans the workflow, and each step in the plan gets matched to the best model for that specific step.
Best for: complex workflows where a single request involves multiple types of tasks — research, analysis, writing, and formatting all in one job.
The Major AI Providers Are Already Doing This
Model routing isn't just a third-party tool. The largest AI companies are building it into their own products.
OpenAI's GPT-5.4 uses an internal router that dynamically selects sub-models per task. Behind the unified "GPT-5.4" interface, different specialized components handle different types of requests. When you ask GPT-5.4 a coding question versus a creative writing question, different internal systems may process each one.
Microsoft's Copilot Researcher now uses multiple models. A GPT model drafts responses. An Anthropic Claude model reviews them for accuracy. Microsoft explicitly adopted a multi-model approach because, as their VP of Design and Research stated, two models checking each other's work produces more reliable results than either model alone.
Google's Gemini architecture routes between different model sizes based on task complexity. Simple queries get handled by smaller, faster variants. Complex reasoning tasks get routed to the full Gemini 3.1 Pro model.
Even models that appear to be a single system often aren't. Many frontier models use a "mixture of experts" architecture internally, where the model itself contains multiple specialized sub-networks and routes each token to the most relevant expert. The concept of routing is baked into the foundation of modern AI.
IDC predicts that by 2028, 70% of top AI-driven enterprises will use advanced multi-model architectures to dynamically manage model routing.
Why Model Routing Matters for Cost
The economic case for model routing is straightforward.
Not every task needs a frontier model. When you use a $15-per-million-token model to classify a support ticket that a $0.10-per-million-token model handles equally well, you're overspending by 150x for zero quality improvement.
Model routing lets you match compute cost to task complexity. Routine tasks — classification, extraction, simple summarization, formatting — go to cheap, fast models. These tasks make up the majority of AI usage in most organizations. Complex tasks — multi-step reasoning, nuanced analysis, creative strategy — go to premium models where the extra capability actually matters.
Studies suggest this approach can cut AI costs by 40-60% compared to using a single premium model for everything, while maintaining or improving overall quality.
For enterprise teams running thousands of AI tasks daily, the cost savings compound quickly. And unlike other cost-cutting measures, intelligent routing doesn't sacrifice output quality — it actually improves it by matching each task to the model best equipped to handle it.
Why Model Routing Matters for Quality
Cost savings are nice, but the quality argument is even stronger.
When you use one model for everything, you accept that model's weaknesses along with its strengths. A model that's excellent at analysis but mediocre at creative writing will produce mediocre creative content — even though a better option exists for that specific task.
Model routing eliminates this compromise. Each task goes to the model where it performs best, not the model you happen to be subscribed to.
In practice, this means:
Writing tasks get handled by models with the strongest natural language capabilities — models that produce coherent, well-structured long-form content.
Coding tasks get routed to models fine-tuned on code — models that understand syntax, debug effectively, and produce production-quality output.
Research and analysis goes to models with the largest knowledge bases and strongest reasoning — models that can synthesize information across many sources and draw non-obvious conclusions.
Fast, routine tasks go to lightweight models that respond in milliseconds — no need to wait 10 seconds for a frontier model to answer a simple yes/no question.
The result is consistently better output across all types of work, even though no single model improved.
What This Means for Vendor Lock-In
The single-model approach creates vendor lock-in by default. If your team standardizes on ChatGPT, your workflows, prompts, and institutional knowledge all become optimized for that one model. Switching providers means relearning, reprompting, and rebuilding.
Model routing inverts this dynamic. Because the routing layer handles model selection, your workflows are model-agnostic. When a new model launches that outperforms the current leader on a specific task type, you update the routing rules. Your team's workflows don't change.
This is especially important in 2026 because the AI model landscape changes constantly. Models leapfrog each other every few months. A model that's best at code in April might be second-best by July. Without routing, you either switch providers (disrupting everyone's workflow) or stick with a model that's no longer the best choice (accepting lower quality).
With routing, upgrades happen at the infrastructure level. Your team keeps working the same way. The models behind the scenes improve automatically.
How to Think About Model Routing for Your Team
If you're evaluating AI platforms for your team, here's how model routing fits into the decision.
If you're a solo user doing one type of work, model routing adds minimal value. Pick the model that's best at your primary task and use it directly. A developer focused on coding should use the best coding model. A writer should use the best writing model.
If your team does diverse work, routing starts to matter. A marketing team that writes content, analyzes data, creates presentations, and processes research would benefit from different models optimized for each of these activities.
If you're processing high volumes, routing is essential. The cost savings from routing routine tasks to cheaper models justify the architectural complexity within days, not months.
If you need long-term flexibility, look for platforms with multi-model support built in. Betting on a single model is betting that one company will win every benchmark forever. That bet has never paid off in technology.
The key questions to ask any AI platform:
How many models does it support? Can you switch models without changing your workflow? Does it route automatically based on task type? Can you see which model handled each request? Can it add new models as they become available?
The Bottom Line
The era of "one model for everything" is ending. Not because any single model got worse, but because the landscape matured to a point where specialization consistently outperforms generalization.
Model routing is the practical answer to this reality. It automatically matches each task to the model best suited for it, improving quality while reducing cost. The major AI companies already use it internally. Enterprise adoption is accelerating. IDC projects that 70% of top AI-driven enterprises will use multi-model routing architectures by 2028.
For teams and organizations, the implication is clear. Don't optimize for finding the perfect single model. Optimize for a system that uses the right model for each task. That's the architecture that delivers the best results at the lowest cost — and the one that stays current as the AI landscape continues to evolve.